I’m still writing. I had a first (bad) draft version out of my mailbox about a week ago, and a first answer 5 days ago (my tutor is that good!).
It turns out the organization of the contents was all wrong, and I should have known, there was a template of sorts. So I re-organized it all, added more content, visuals, etc.
The current version, let’s call it (bad) draft 0.2, feels a bit better overall. I mean, I have the impression it is starting to actually look like something.
Thank goodness I have taken (many) screenshots over the past few months, it has helped quite a bit.
The issues
I think I mentioned it, I recently implemented a “Mean-Field” approach (called “MMCA”) to the SIS simulator, by directions of my tutor, to add quality, weight… “value”, let’s say, to my dissertation and overall project.
And after the implementation, of course I ran it a bunch of times and looked at comparing things with the (original, slower, but conceptually more direct) former Monte-Carlo (or MC) implementation.
Immediately I saw the differences, and with the advice from my tutor, we came up with (I feel) reasonable explanations. My project makes things a bit different from “traditional” SIS simulator. But so far, so good…
Until I tried to compare the GA results with MC and with MMCA, for identical configurations. I did understand that the GA is non-deterministic, so I didn’t expect the same results for a given configuration, and I had explained how the MMCA approach would return higher prevalences, particularly for high Mu and low Betas (which can be observed next).
But still, something was bothering, for one thing: the MMCA approach provided results that looked “smoother” across configurations, mostly for higher budgets
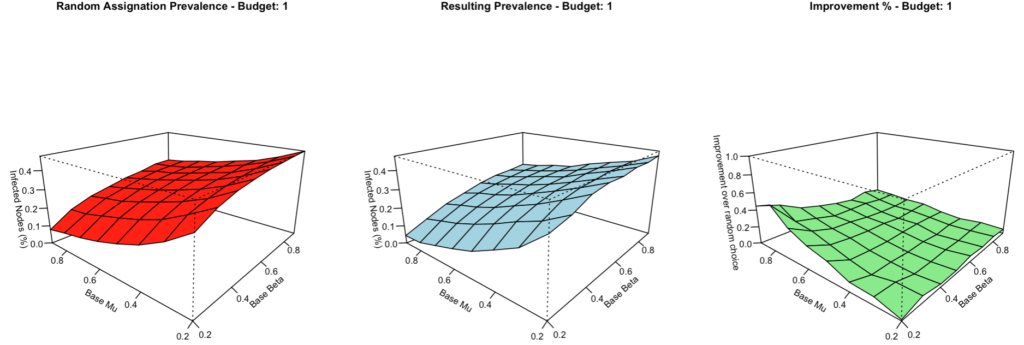
And the MMCA approach “appears” to do much less progress, yes, but in comparing the best resulting individuals with both approaches, while multiplying the iterations of the MC, both algorithms generally agreed on their approximate “value”. What’s more, sometime the GA provided better individuals with MMCA than with MC, and vice-versa.
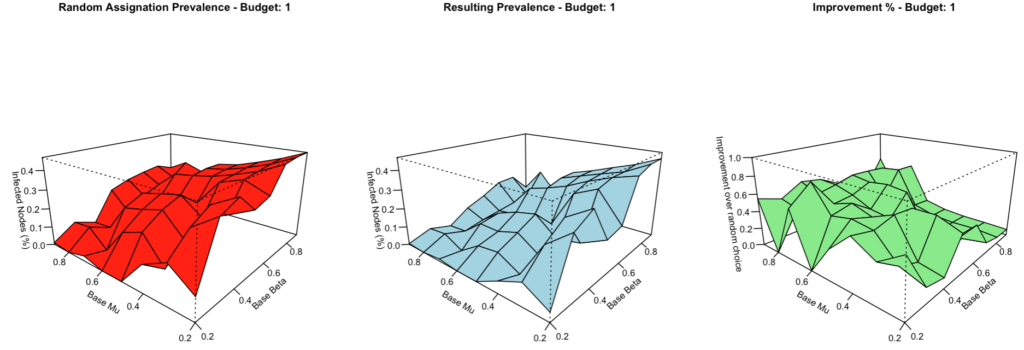
In other words, the smoothness differences did NOT seem to be explained “simply” by the choices of the GA. Actually, it appears FIRST in the random assignation of the budget…
Thank goodness I have my Shiny Dashboard by now, whereby comparing results can be done with a few clicks, not running lines of code, it’s much “cleaner” and less error-prone…
By now it is clear, the GA is not deterministic. But on top of that, our MC is itself NOT AT ALL deterministic, and maybe there is something about that…
While comparing the MMCA and the MC, I somehow concluded I must have made an “optimization” mistake somewhere. 🙁
The “Monte-Carlo” approach is meant to control for the non-deterministic nature of such stochastic algorithms as that used for our SIS simulator, full or random value generations… What I wonder about most right now, my current hypothesis: had I chosen to do MANY MORE repetitions per individual in the GA (per parameters set), the averaged results would be much smoother, there would be less variance, I have confirmed that while trying to compare identical individuals…
In other words, a parameter that I purposefully limited (now I know it: I limited it A LOT) might have had an impact in a few (thankfully not many) of the actual results of the MC simulations. What’s more: As I tried to improve the efficiency, I skipped certain (in theory unnecessary) re-runs of already evaluated individuals. This only made sense: If the simulator works, I shouldn’t need to re-run the complete evaluations for all individuals of a generation, but rather only on the new ones.
What this has implied is that, with somewhat insufficient repetitions, I introduced a certain amount of variance in the results PER INDIVIDUAL, per generation, of the GA – and by optimizing and not re-evaluating them, I eliminated the potential for self-correction.
So certain individuals, in one parameter set, are evaluated and found to have a good fitness (low infection prevalence), but because of the low amount of repetitions, it could be an effect of a high variance and an uncommonly low value for a given configuration. And so such individuals, which are maybe in fact not as good as they appear, are kept across (potentially many or all) generations, influencing the whole GA process afterwards…
How bad is it?
At this point, it’s really only a theory. Something more bothers me: the lack of smoothness is NOT introduced by the GA, as the INITIAL generation already exhibits it. So it would appear the issue is possibly somewhere else…
But let’s say, for exercise purposes only: supposing my (current) theory holds (it should not…): Well, then in theory, it’s not great: I should have found earlier I needed more repetitions to ensure a lower variance.
However, in practice, AND GIVEN MY ACTUAL OBJECTIVES, it would still not be all that bad. The GA does improve. Simply, maybe less than it probably otherwise could.
Now I COULD in concept re-run whole sets of configurations. But with (much) HIGHER number of repetitions per individual, the runtimes will increase by a factor of (with the numbers I manage) 20, or more. For one configuration? Maybe, sure, why. For all configurations on all networks, we’re talking months, with my current gear. So maybe I should, if I really need to, consider going to the Cloud now?
And if time permits, I still might.
But first I really need to understand this better… That’s my next step.
Then again…
I might be all wrong right now.
And on the other hand, the introduction of the MMCA approach eliminates this repetition issue altogether, so far apparently it works as expected (although the prevalence numbers found are higher than with MC, which I have explained and justified in my dissertation) AND reduces runtimes by a factor of (roughly) 15!
So now I might instead choose to run my (many) configurations using MMCA, which is what I eventually very well might do. I just want to better understand what happened with the MC irregularities…